

Also known as a spider bot or a spider, a web crawler is a bot that indexes website content on search engines and organizes them into search results. Once a webpage is uploaded to the internet, the web crawler will learn what it is all about so that when the information is needed, it is easily retrieved.
So what is a crawler, and why do website owners need to know what they are?
What Is a Web Spider, and How Does It Work?

Image Source: searchenginejournal.com
As the name suggests, a web spider or crawler is a bot that automatically accesses a website and collects the data using a software program. This process is known as website crawling and is at the core of every search engine. Since there are billions of data sets on the internet, bots ensure a user finds what they are looking for by indexing the data sets.
The process of sorting out this information is known as indexing. Have you ever seen a book index, where topics in a book are organized into a list with page numbers to find them in? Similarly, indexing on the internet allows the bot to know where exactly to take you when you search for a topic.
When indexing, the bot learns the text used in the webpage by looking at the keywords and titles. The bot also uses a meta-description and meta-title as part of meta-tags to do searches. However, these are attributes the user never gets to see.During indexing, a bot may add all the words on a page on the index. These words exclude terms like a, an, the, and so on.
When a user searches, the bot goes through its index and shows the user the most relevant results. This is why it is important to use the most relevant keywords when creating content for your website.
A bot can crawl the internet using hyperlinks from one major page to another to retrieve information that will be in the search results once a user has made a search on the internet. For instance, if a page links to another page with similar content, bots take note of that and index such pages. Once indexed, the pages will be retrieved, thanks to the links.
Web crawling is often confused with web scraping. How different are those two?
Web Crawling vs. Web Scraping

Image Source: datadeck.com
Web crawling seeks to index and find web pages, while web scraping is the collection of data from the web. Web scraping extracts the codes used in the HTML and the data within a database. After scraping, a bot can replicate the entire website information elsewhere.
For website owners, web crawling is an important part of SEO that needs a lot of attention. So, why are web crawlers important for SEO?
Why Are Web Crawlers Important for SEO?

Image Source: seozoom.com
Since crawlers are responsible for indexing, anyone who wants their webpage to rank well has to pay attention to what crawlers are looking for.
So, where do web crawlers and SEO meet?
How does Web Crawling Affect SEO?
Web crawlers need to discover and index your page for other people to find the page, and making your page easy to crawl should be one of your SEO strategies. A crawler is essential for SEO because it ranks web pages from most to least relevant. The more pages there are about a certain topic, the better your content on the same topic needs to be for your page to rank well.
The SERP (search engine results page) is a battlefield, and everyone is fighting to be on the very first page.
Before you worry about ranking, you need to ensure that your site has been indexed. How can you know if your site has been indexed?
How to Know if Your Site is Indexed

Image Source: analyticahouse.com
To see how many pages on your website are indexed, you can follow a simple formula on Google;
site:domain.com
For example, for a company called “Indexsy,” this search would apply;
site:indexsy.com
Now that we have established that your site needs to be crawled to be indexed, what is a crawl budget?
What Is Crawl Budget?

Image Source: datanami.com
The crawl budget relates to the number of pages that search engines crawl on any given day. Additionally, how many times the spiders go over your domain is also considered your crawl budget.
The number of pages crawled varies depending on how well taken care of the pages are because it will either be easy or hard for the bots to crawl.For instance, if your pages have too many errors or a lot of unnecessary links, fewer will be crawled as the bots will shelf the pages to crawl them later, and this reduces the crawl rate. When your sites are crawled at a slower rate, it affects your ranking on Google.
There are many reasons why Google would need to crawl your site.
- If some changes are made to your site, Google will have to note them.
- If someone mentions you on Twitter, it will need to take note of it, and it does so by crawling.
- When a new link or URL is created.
If you have a large site, you need to pay attention to how Google crawling is taking place because it will either make your page indexing faster or slower.
Guide to Managing Crawl Budget
Image Source: bestproxyreviews.com
If you have a large site with multiple pages, Google bots will make a list of the available URLs that it will need to crawl later. The bots create something in the form of a to-do list for crawling. If you have a large site, the “list” will be longer, and there will be a need to go through it faster. For this reason, you need to make it easier for the crawlers to do their job efficiently for your pages to be indexed and ranked as often as possible.
Remember, the more your pages are crawled, the faster they are indexed.
Here are some things large site owners can do to improve their crawl budget.
1) Use Robots.Txt
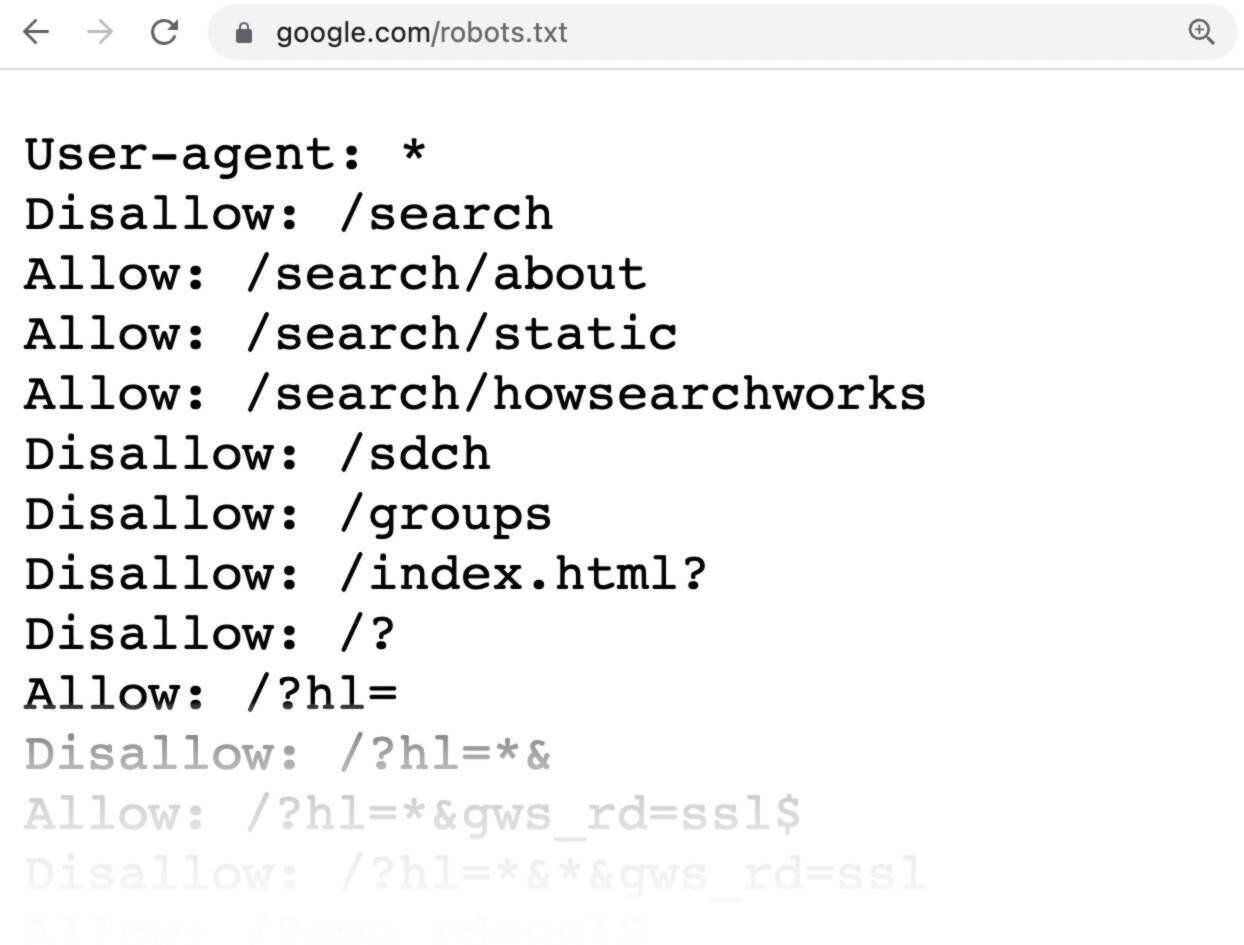
Image Source: semrush.com
Robots.Txt can be the main difference between slow and fast indexing. Robots.Txt helps you choose which URLs the crawlers can access and which ones to avoid. This makes it easier to control crawler traffic on your page instead of letting crawlers deal with a large portion of URLs.
You can add Robots.Txt by yourself, which gives you all the control and focuses the crawlers on the most relevant pages. There are a few limitations that come with Robots.Txt that you need to be aware of.
First, Robots.Txt may not be supported by some major search engines. Luckily, Google is all you need to worry about most of the time because of the ecosystem around it. Even when the search engines support Robots.Txt, there are crawlers that may interpret Robots.Txt syntax and rules differently. However, most web crawlers follow the rules set by Robots.Txt.
A page may block Robots.Txt and still be indexed if there is another page linking to it. One way to avoid such a situation is to protect the files on your server using a password to keep them from getting indexed.
2) Reduce Errors on Your Server

Image Source: xeonbd.com
Return codes are messages a server returns to a program showing the status of a request. If the processing of a request is unsuccessful, you will get an error code. If you are getting a return code other than 200 or 301, then your server might have errors. For example, error 404, 400, and 401 are error return codes.
You can take a look at your server log to know whether you will have error return codes or not. This is important because Google Analytics will only look at pages with a 200 return code, which is essential information you need to improve your SEO.
Once you have established the problematic return codes in your server log, you canfix error return codes or redirect the URLs elsewhere using a redirects manager.
3) Reduce Redirect Chains
Image Source: ventsmagazine .com
Earlier, we discussed what return codes you can get when you make a search. While you should have 301 as one of the return codes in your server log, they increase crawl time. This is because once crawlers have taken note of a redirect, they do not crawl it immediately but rather place it in the “to-do list” to crawl it later. This might reduce your crawl budget.
4) Avoid Duplicate Content
Google would rather not use its resources indexing duplicate content. This is why it is important to be unique when publishing content.
5) Make Good Use of Links
Google prioritizes sites with a lot of links pointing toward them. Such sites exhibit credibility signs. You can add internal links, which will, in turn, get Google’s attention. Remember, Google bots follow links, and when you use internal links, they will follow those links to the pages you need to be indexed, increasing the crawl rate.
6) Avoid Orphan Pages
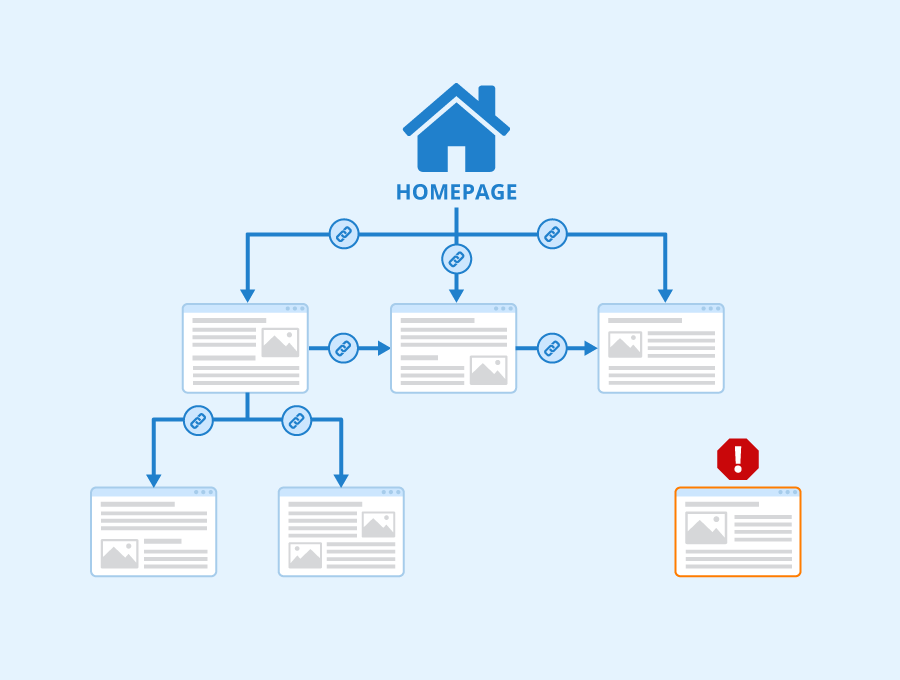
Image Source: seobility.net
An orphan page is a page that has no link pointing toward it. Google has a hard time finding such a page on your web server.
7) Use HTML

Image Source: oxfordwebstudio.com
If you are using Google, it is better to use HTML on your websites instead of JavaScript. This is because HTML will get crawled relatively faster by bots, compared to JavaScript, which is not crawled fast when using Google as the search engine. This has a direct impact on a site’s crawl budget.
8) Increase Your Page Loading Speed

Image Source: popupsmart.com
If your site is slow, the crawl budget will be low. You can make your site faster by avoiding large images or bulky resources. Your site speed should be adequate enough to respond to requests in a timely manner.
9) Monitor Your Site’s Crawling and Indexing

Image Source: agence90.fr
There are methods you can use to know whether crawling is going on on your website. First, you can check the status of your URL in the Google index. If a page was not indexed, you can see why by checking if the page is indexable.
If you need a URL to be indexed by Google, you can place a request and have it indexed. Additionally, you can troubleshoot missing pages or even see what the bot sees on your page by requesting a rendered version.
10) See if Updates are Crawled Quickly Enough

Image Source: onely.com
You can check your crawl stats report to see the crawl history on your website. You can see the number of requests made, when they were made, how the server responded, and any issues encountered on your page.
The information further helps you see if Googlebot is encountering any availability issues on your site.
How to Stop Bots from Crawling My Site
There can be instances where you would want to stop a bot from crawling your site. For example, when you are still working on your site, updating it, making changes, or archiving it, it would be unnecessary for bots to crawl the pages. So, how can you stop bots from crawling your site?
a) Use Robots.txt
As discussed earlier, robots.txtcontrols how crawlers behave on your site by telling them which sites to crawl and which to ignore.
b) HTTP Authentication
HTTP authentication requires a username and password before any activity happens on your site, including crawling.
c) CAPTCHAs
CAPTCHAs are a method used to tell humans and robots apart. They require a user to complete a simple task that robots usually cannot do. So, CAPTCHAs can keep crawlers away.
d) Block IP Addresses
If a specific IP address directs unwanted traffic toward your site, you can block it. Traffic often includes links, which point bots your way in most cases.
e) Noindex Tag
Noindex is a tag that makes Google get rid of a page from its search results. Such a page would be invisible even if other pages were linked to it.
Why would anyone want to stop bots from crawling their site?
- Bots can use up some of your website server’s resources, including bandwidth and processing power.
- Some bots are malicious. For instance, bots are designed to scrape and copy content from your page.
- Malicious robots can inject spam and malicious code into your server.
- When you are still working on your page, making changes, changing the content destination, and maintaining your page.
Frequently Asked Questions Web Crawlers
i) Why are Google bots called spiders?
Most users access the internet on the world wide web. Since the bot crawls all over the “web,” they form imagery of what spiders do.
ii) What is an example of a web crawler?
There are various types of crawlers for different search engines. For instance, Bing uses Bingbot, Amazon- Amazonbot, Google- Googlebot, DuckDuckGo- DuckDuckbot, and more.
iii) Are web crawlers used for data mining?
Web crawlers can be used for data mining, which is the process of gathering information in large volumes. The data can be used to study patterns and look at relationships in data patterns.
Final Thoughts

Image Source: crayondata.com
While your website’s crawl budget is not the sole reason why your ranking goes up, it plays a vital role in ensuring your sites are found and ranked. You have to pay a lot of attention to getting your page optimum for crawling, especially if you run larger sites, to get them indexed frequently.
Featured Image Source: euronews.com

1