

Everyone wants Google to rank their website higher in search, and with 93% of all Internet traffic beginning with a search engine, ranking in Google presents a top digital marketing opportunity for reaching consumers and increasing conversions. However, not every website can make it to the top of the rankings.
For starters, Google’s algorithms prioritize pages that provide the greatest value to consumers. Not to mention, before you can even think about ranking, you must first verify that Google knows your site exists. Therefore, it is imperative to include your website in Google’s search index. But are you wondering how to get Google to crawl your site and how Google indexing affects your search engine optimization (SEO)?
Here, I’ll go through the Importance of Google Crawling and How to Get Your Website indexed. Keep reading to learn more!
What is Google Crawls?
Google strives to give users the most recent and relevant material. Googlebot, the search engine’s robot, therefore scans websites to find relevant material to display when users conduct searches on Google.
Image Source: linkilo.co
Consider Google’s website crawling as Googlebot scouring websites for fresh or updated material to index. Videos, photos, blog entries, and PDFs are all examples of indexed material.
Finding a web page is the first step in the crawling process. After locating a web page, Googlebot explores the page’s other connections to locate more information that needs to be crawled.
What Exactly Is Indexing?

Image Source: analyticahouse.com
Indexing is the process of assessing and storing the content of crawled webpages in a database (also known as Google’s index. ). Only pages that have been indexed can be ranked and utilized in relevant search searches.
When a web crawler finds a new webpage, Googlebot sends its content (e.g., text, photos, videos, meta-tags, attributes, and so on) into the indexing phase, where it is processed for a better understanding of the context and saved in the index.
What Distinguishes Crawling and Indexing From One Another?
Crawling is the process of discovering sites and links that lead to further web pages. Indexing is a technique of storing, assessing, and organizing information and links between sites. There are elements of indexing that influence how a search engine crawls.
What Is the Importance of Website Crawling and Indexing?
To raise a website’s search engine optimization (SEO) ranks, website crawling and indexing are essential. All online pages, including some that search engines might have overlooked, are indexed by web crawlers. Additionally, frequent crawling and updates can improve a website’s SEO ranking, especially for information that must be updated quickly.
Access restrictions and errors both have a big impact on SEO. Making sure that web pages can be crawled by search engines is crucial. In order to facilitate a site’s crawling, a sitemap should also be sent to search engines. Finally, routine website crawling and indexing can help with SEO and make sure that your website is accessible to potential clients on search engines.
How Do You Get Google to Crawl and Index Your Website?

Image Source: techprevue.com
When it comes to real crawling and indexing, there is no “direct command” that will cause search engines to index your site. There are, however, various techniques to affect if, when, and how your website is crawled and indexed.
So, let’s see what your options are for “telling Google about your existence.”
1. Do Nothing at All—a Passive Approach
Technically, you don’t need to do anything to get your site crawled and indexed by Google.
All that’s required is one external website link, and Googlebot will begin crawling and indexing all available pages.
Taking a “do nothing” approach, on the other hand, may cause a delay in crawling and indexing all your pages because it may take a while for a web crawler to discover your website.
2. Use the URL Inspection Tool to Submit Websites.

Image Source: platinumseo.com.au
Request indexing using the URL Inspection Tool in Google Search Console is one of the methods you may use to “secure” the crawling and indexing of certain web pages.
When you want to index a new page as soon as possible or when you’ve made significant changes to an existing page, this tool is helpful. The procedure is fairly easy:
- Enter your URL in the search box at the top of the Google Search Console.
- You can view the page’s status in the Search Console. You can ask for indexing if it isn’t already done. If you make any significant modifications to the page after it has been indexed, there is no need for further action or requests.
- After a few seconds or minutes, the URL inspection tool will begin determining if the live version of the URL can be indexed.
- Upon successful completion of the testing, a message will appear to confirm that your URL has been assigned to a priority crawl queue for indexing. The time it takes to index a document might range from a few seconds to many days.
Remember, if you just have a few websites that you wish to index, this way of indexing is advised; do not misuse this feature.
Making an indexing request does not ensure that your URL will be indexed. The URL could not be indexed at all if it is prohibited from crawling and/or indexing or has certain quality concerns that are in conflict with Google’s quality requirements.
3. Manage the Noindex and Canonical Tags.
The use of the robot’s SEO meta tag with a “noindex” value is one approach to instruct search engines not to index your pages.
It appears as follows: <meta name=”robots” content=”noindex”>
This piece of code instructs Google not to index a page if it appears on it. Google Search Console allows you to determine whether pages on your website contain rogue noindex tags.
- Click the “Pages” report in the left menu’s “Indexing” subsection.
- Scroll all the way down to the section under “Why pages aren’t indexed.
- Find the text that says “Excluded by the “noindex” tag” there. Toggle it.
- By using the noindex tag.
- Remove the noindex meta tag from the source code of the URL in the list if you want it to be indexed.
Additionally, the Site audit tool will alert you to any pages that have been blocked by the robots.txt file or the noindex tag. Plus, it will alert you to any resources that have been blocked by the so-called X-Robots tag, which is typically applied to non-HTML documents (like PDF files).
The canonical tag on your website is another factor that can prevent it from being indexed.
Crawlers may determine which version of a page is preferred using canonical tags. They avoid problems brought on by duplicate material that appears on several URLs.
When a page’s rogue canonical tags point to a different URL, Googlebot interprets this as indicating that there is a separate preferred version of the page. And even if there isn’t an alternative version, search engines won’t index the page with the canonical tag.
This time, Google Search Console’s “Pages” report will be useful. Simply click the “Alternate page with the proper canonical tag” reason after scrolling down to the “Why pages aren’t indexed” section.
A list of all the web pages that have been affected will appear. Look over the list.
Remove the rogue canonical tag from the page if it is a page you want to be indexed but the canonical tag is being applied erroneously. Alternatively, be certain that it directs to the version of the webpage you would like to be indexed.
4. Include the Page in Your Sitemap.
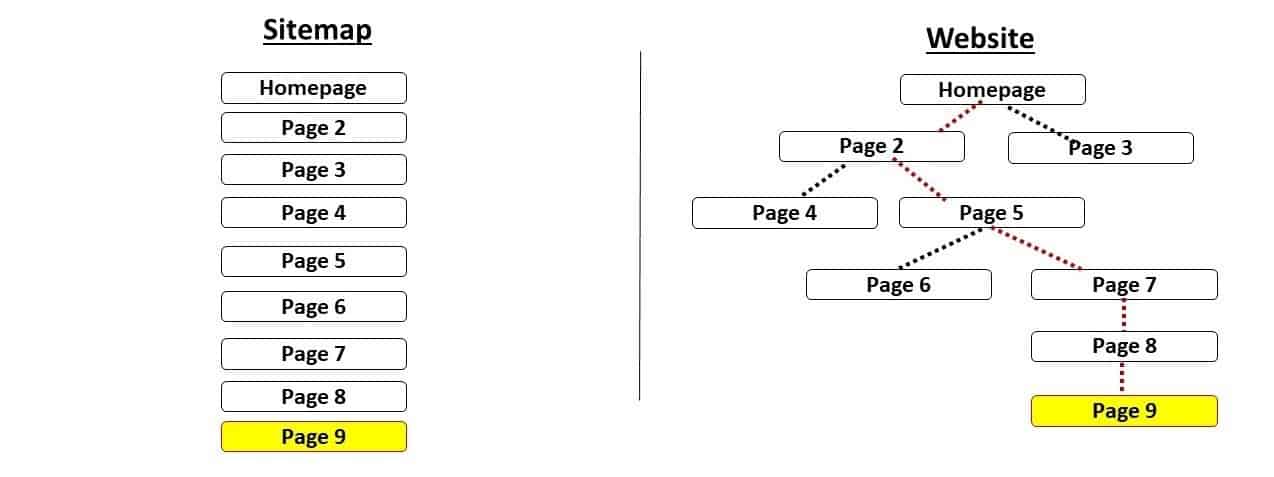
Image Source: theegg.com
A sitemap is a list or file in XML format that comprises all of your web pages that you would like search engines to scan or index.
The primary advantage of sitemaps is that they make it simple for search engines to index your website. You may submit a large number of URLs at once, which can speed up your website’s overall indexing process. You’ll use Google Search Console again to notify Google about your sitemap.
5. Remove Crawl Blocks in Your robots.txt File.
Is Google failing to index your full site? It can be due to a crawl block in a file called robots.txt. Go to yourdomain.com/robots.txt to look for this issue.
It will provide you with two codes. Both of these inform Googlebot that it is not permitted to crawl all the pages on your site. Remove these to resolve the problem. It’s as easy as that.
6. Add “Powerful” Internal Links

Image Source: getfoundquick.com
Google crawls your website to find new material. If you fail to include an internal link to the relevant pages, they may be unable to discover them. Internal link-building will help accelerate the indexing process.
If you wish to audit your internal links, go to the “Internal Linking” theme report in Site Audit. The report will detail all of the concerns with internal linkage.
Of course, fixing all of them would be beneficial. However, three issues are critical when it comes to crawling and indexing:
- Outgoing internal links contain nofollow attributes: Nofollow links do not convey authority. When the target page is used internally, Google may choose to ignore it when crawling your site. Make sure you’re not using them on pages you want to be indexed.
- Pages require more than three clicks to reach: There is a potential that sites won’t be crawled and indexed if they require more than three clicks to access the homepage. On these pages, add more internal links and take a look at your website’s architecture.
- Missing pages in the sitemap: Orphan pages are those that do not have any internal links going to them. Rarely do they get indexed? Create links to any orphaned pages to resolve this problem.
7. Enhance the Overall Quality of Your Site.
Technical problems are not the only cause of indexing troubles. Even if your website meets all technical standards for indexing, Google could not include all of your pages in its database, especially if Google does not think highly of your website.
If this is the case for you, you might want to start by concentrating on the following:
- Enhancing the website’s content quality
- Creating high-quality connections to your website
- Increasing your website’s expert, authoritative, and trustworthiness (E-A-T) signals
How Do You Check If Google Has Indexed Your Site?

Image Source: wordstream.com
There are different ways to determine if webpages have been crawled and indexed or whether a certain webpage has problems.
1. Perform a Manual Check.
The simplest approach to determining whether or not your website has been indexed is to use the site operator:
If your website was crawled and indexed, the “About XY results” section should show all of the indexed pages as well as how many of your pages Google indexed. If you would like to see if a certain URL has been indexed, use the URL rather than the domain. If your page got indexed, you should be able to get it in the Google search results.
2. Examine the Index Coverage Status.
You may utilize the Index Coverage Report in Google Search Console to gain a more complete overview of your indexed (or not-indexed) sites.
Charts containing details in the Index Coverage Report can give useful information about URL statuses and the sorts of difficulties with crawled and/or indexed sites.
3. Use the URL Inspection Tool.
The URL Inspection tool can offer information on particular websites on your website that has been crawled since the last time they were inspected. You can determine whether your website:
- Contains several flaws (with information on how they were identified).
- Was crawled, and when it was crawled last
- If the page is indexed and can show up in search results,
Common Mistakes Prevent Crawlers From Seeing Your Entire Site

Image Source: josephmuciraexclusives.com
- A mobile navigation system that displays different results from your PC navigation.
- Any kind of navigation where the items in the menu are not contained in HTML, such as navigations supported by JavaScript. Despite the fact that Google has considerably increased its capacity to crawl and understand Javascript, the process is still far from ideal. Including anything in HTML is the most reliable approach to making sure it is read, comprehended, and indexed by Google.
- Failure to add a link to a critical page in your navigation. Bear in mind that internal links are the routes web crawlers take to find new content!
- Personalization, or providing different navigation to different types of visitors, may appear to a search engine crawler to be cloaking.
Final Take
In conclusion, website crawling and indexing are essential for Search Engine Optimization performance. You may speed up the indexing of your website and increase your chances of ranking better in search engines by optimizing it and putting the correct measures in place. When done correctly, website crawling and indexing may assist you in more quickly and effectively achieving your SEO objectives.
